
| Hier kan PEGA Content staan | Hier staat een ArcGIS kaartje |
|---|---|
| iframe title="PEGA inhoud" src="url" /iframe | |
| Leuk plaatje | En wat tekst |
 |
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum. |
FME GeoRSS uitlezen met paged datasets
Begrenzing op data services
Sommige RSS feeds zijn begrensd op het aantal geretourneerde objecten. Een voorbeeld is de dataset van het Nederlandse bureau voor de statistiek, CBS. Het is interessant om te kijken hoe je daar in FME mee omgaat.Achtergrond
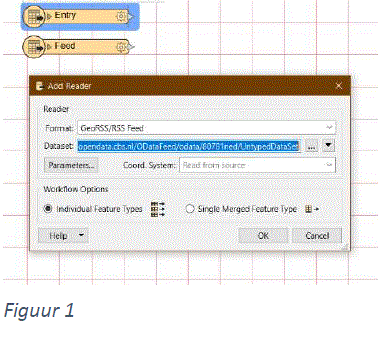
FME kent een ongelofelijk aantal readers om allerlei soorten data in te lezen. Eén daarvan is de GeoRSS Feed Reader (Figuur 1). FME splitst GeoRSS datasets in:RSS is een protocol dat gebruikt wordt voor het distribueren van data, gebruikers en applicaties krijgen er op een gestandaardiseerde, voor computers leesbare manier toegang mee tot data en updates van die data. Gebruikers worden daarbij ontlast van de controle op updates en het downloaden van data. Om de belasting van servers die dergelijke data serveren te beperken, is voor veel van dergelijke weblocaties een maximum gezet op het aantal direct te downloaden records. Wanneer je in FME een GeoRSS Reader gebruikt om, b.v. initiële versies van, datasets te downloaden, zal FME alleen het op de server geconfigureerde maximum aantal objecten terugontvangen. Maar wat als nu een complete dataset nodig is?
Data en meta gegevens
Gelukkig worden deze datasets vaak gepagineerd aangeboden. Nadat de eerste bulk data binnen is, geeft de server ook nog een (meta-) record af, waarin een verwijzing naar het volgende blok data staat. FME splitst deze meta records af als een ander feature type uit de reader. Dit kan gebruikt worden om informatie af te leiden over de volgende set records (Figuur 2). De payload van de data komt binnen via het ‘Entry’ feature type, en de meta records komen de workspace in via het feature type ‘Feed’. Al wat nodig is, is controleren of er records worden aangeboden uit de ‘Feed’, en deze te verwerken. Hiervoor is het nodig informatie te verwerken nadat de informatie waar het om te doen is, in de FME workspace is binnen gekomen. FME kent daar een aantal manieren voor, waarvan ik er één hier nader uit zal werken.
Aanpak
Hiervoor moet onderscheid worden gemaakt in het verwerken van de informatie waar het om te doen is, en de meta informatie. Voor de payload kan een workspace gemaakt worden die één blok data verwerkt en opslaat. Daarnaast kan een workspace worden gemaakt om de meta informatie te verwerken; deze zal meestal de data processing workspace aanroepen, bijvoorbeeld met een WorkspaceRunner. Een variant hierop is publicatie van de payload workspace naar FME Flow, waar ze een onderdeel is van een groter geheel dat een lokaal Geodatawarehouse vult en actueel houdt. Daarvoor zullen meestal meerdere workspaces geschreven moeten worden, en in een logische volgorde gestart. FME is in de basis een ETL tool, waarmee snel een grote set gegevens ingelezen, getransformeerd en doorgesluisd kan worden naar een doellocatie. Om daarmee in een enkele workspace een dataset te verwerken waarvan de inhoud afhankelijk is van die inhoud zelf, moet een bijzondere truc worden toegepast: een custom transformer die looping gebruikt (Fig. 3).
Uitleg
De input poort en de ParameterFetcher halen informatie op over de GeoRSS feed bron, en voedt deze aan de FeatureReader (Figuur 4). Deze haalt de eerste lading objecten op, en op de Feed poort komt de meta-informatie binnen, met o.a. informatie over de volgende set objecten (Figuur 2).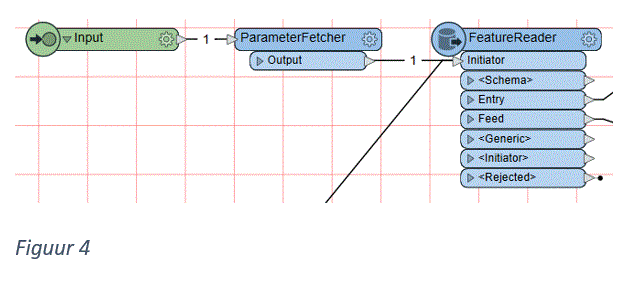
Door deze beschikbaar te maken in de workspace (AttributeExposer), te doorzoeken op een verwijzing naar de volgende set (‘next’, ListSearcher) en de bijbehorende URI uit te lezen (AttributeCreator) weet de workspace de URI voor de volgende call naar de GeoRSS reader (Figuur 5). Door nu dit resultaat via de loop weer in te spoelen in de FeatureReader, wordt de volgende set gegevens opgehaald. Deze setup is een grove schets, verfijningen kunnen aangebracht worden aan de Rejected poort van de FeatureReader (“wat gebeurt er met invalide RSS bronnen?”) of de ListSearcher (“wat als er geen extra meta-informatie beschikbaar is?”).

Ook kunnen verschillende RSS bronnen andere meta-informatie terugleveren en zal het in voorkomende gevallen nodig zijn op andere waarden te zoeken of attribuutnamen te wijzigen. Maar het mechanisme is duidelijk en werkt b.v. bij informatie van opendata.cbs.nl. Duidelijk is ook in de logging (Figuur 6) te zien dat de informatie in twee blokken wordt opgehaald voor, in dit geval, een dataset met 17.043, en een limiet van 10.000 objecten.

Voordelen
Het voordeel van een dergelijke aanpak is dat slechts één workspace gebruikt wordt voor het ophalen van een complete dataset, en verder geen bijzonder systeem voor registratie hoeft te worden ingericht. Via de GeoRSS reader kan de standaard informatie die FME hiervoor bijhoudt gebruikt worden (Figuur 7). In de feedstore worden kleine databases bijgehouden met informatie over de feeds die de GeoRSS-lezer heeft verwerkt. Deze databases worden alleen gelezen als de reader in updatemodus draait. Wanneer de workspace geautomatiseerd wordt gedraaid, kan de parameter voor de Reader Mode worden gepubliceerd. Voor de initiele vulling van de datawarehouse tabel kan dan incidenteel de waarde “Normal” worden meegegeven, maar in de maandelijkse automatische run zal de waarde “Update” ingevuld worden. Dan worden alleen records aangeboden die gewijzigd zijn sinds de – in FME geregistreerde – datum. Vanzelfsprekend zal de workspace aangepast moeten worden, zodat de updates ook daadwerkelijk in de correcte modus worden geschreven in de uiteindelijke writer.
Ingebouwde functies
FME is een intuïtieve en krachtige tool. Initiële vulling en bijhouding van datawarehouse tabellen is, zeker wanneer die tabellen ook een geo-component bevatten, typisch een taak voor FME. Vaak worden in FME echter complexe systemen gebouwd, waarbij delen van de gebouwde functionaliteit deel uitmaken van ingebouwde functies in FME. Dat die, zoals in dit geval, minder direct voor de hand liggen, maakt voor mij FME eigenlijk alleen maar leuker.FME 2019: Een nieuwe instelling voor de CenterLineReplacer
FME GeoRSS Reader en paged datasets
Begrenzing op data services
Sommige RSS feeds zijn begrensd op het aantal geretourneerde objecten. Een voorbeeld is de dataset van het Nederlandse bureau voor de statistiek, CBS. Het is interessant om te kijken hoe je daar in FME mee omgaat.
Achtergrond
FME kent een ongelofelijk aantal readers om allerlei soorten data in te lezen. Eén daarvan is de GeoRSS Feed Reader (Figuur 1). RSS is een protocol dat gebruikt wordt voor het distribueren van data, gebruikers en applicaties krijgen er op een gestandaardiseerde, voor computers leesbare manier toegang mee tot data en updates van die data. Gebruikers worden daarbij ontlast van de controle op updates en het downloaden van data. Om de belasting van servers die dergelijke data serveren te beperken, is voor veel van dergelijke weblocaties een maximum gezet op het aantal direct te downloaden records. Wanneer je in FME een GeoRSS Reader gebruikt om, veelal initiële versies van, datasets te downloaden, zal FME alleen het op de server geconfigureerde maximum aantal objecten terugontvangen. Maar wat als nu een complete dataset nodig is?
Data en meta gegevens
Gelukkig worden deze datasets vaak gepagineerd aangeboden. Nadat de eerste bulk data binnen is, geeft de server ook nog een (meta-) record af, waarin een verwijzing naar het volgende blok data staat. FME splitst deze meta records af als een ander feature type uit de reader. Dit kan gebruikt worden om informatie af te leiden over de volgende set records (Figuur 2). De payload van de data komt binnen via het ‘Entry’ feature type, en de meta records komen de workspace in via het feature type ‘Feed’. Al wat nodig is, is controleren of er records worden aangeboden uit de ‘Feed’, en deze te verwerken. Hiervoor is het nodig informatie te verwerken nadat de informatie waar het om te doen is, in de FME workspace is binnen gekomen. FME kent daar een aantal manieren voor, waarvan ik er één hier nader uit zal werken.
Aanpak
Hiervoor moet onderscheid worden gemaakt in het verwerken van de informatie waar het om te doen is, en de meta informatie. Voor de payload kan een workspace gemaakt worden die één blok data verwerkt en opslaat. Daarnaast kan een workspace worden gemaakt om de meta informatie te verwerken; deze zal meestal de data processing workspace aanroepen, bijvoorbeeld met een WorkspaceRunner. Een variant hierop is publicatie van de payload workspace naar FME Flow, waar ze een onderdeel is van een groter geheel dat een lokaal Geodatawarehouse vult en actueel houdt. Daarvoor zullen meestal meerdere workspaces geschreven moeten worden, en in een logische volgorde gestart. FME is in de basis een ETL tool, waarmee snel een grote set gegevens ingelezen, getransformeerd en doorgesluisd kan worden naar een doellocatie. Om daarmee in een enkele workspace een dataset te verwerken waarvan de inhoud afhankelijk is van die inhoud zelf, moet een bijzondere truc worden toegepast: een custom transformer die looping gebruikt (Fig. 3).
Uitleg
De input poort en de ParameterFetcher halen informatie op over de GeoRSS feed bron, en voedt deze aan de FeatureReader (Figuur 5). Deze haalt de eerste lading objecten op, en op de Feed poort komt de meta-informatie binnen, met o.a. informatie over de volgende set objecten (Figuur 2). Door deze beschikbaar te maken in de workspace (AttributeExposer), te doorzoeken op een verwijzing naar de volgende set (‘next’, ListSearcher) en de bijbehorende URI uit te lezen (AttributeCreator) weet de workspace de URI voor de volgende call naar de GeoRSS reader (Figuur 6). Door nu dit resultaat via de loop weer in te spoelen in de FeatureReader, wordt de volgende set gegevens opgehaald. Deze setup is een grove schets, verfijningen kunnen aangebracht worden aan de Rejected poort van de FeatureReader (“wat gebeurt er met invalide RSS bronnen?”) of de ListSearcher (“wat als er geen extra meta-informatie beschikbaar is?”).
Ook kunnen verschillende RSS bronnen andere meta-informatie terugleveren en zal het in voorkomende gevallen nodig zijn op andere waarden te zoeken of attribuutnamen te wijzigen. Maar het mechanisme is duidelijk en werkt b.v. bij informatie van opendata.cbs.nl. Duidelijk is ook in de logging (Figuur 4) te zien dat de informatie in twee blokken wordt opgehaald voor, in dit geval, een dataset met 17.043, en een limiet van 10.000 objecten.
Voordelen
Het voordeel van een dergelijke aanpak is dat slechts één workspace gebruikt wordt voor het ophalen van een complete dataset, en verder geen bijzonder systeem voor registratie hoeft te worden ingericht. Via de GeoRSS reader kan de standaard informatie die FME hiervoor bijhoudt gebruikt worden (Figuur 7). In de feedstore worden kleine databases bijgehouden met informatie over de feeds die de GeoRSS-lezer heeft verwerkt. Deze databases worden alleen gelezen als de reader in updatemodus draait. Wanneer de workspace geautomatiseerd wordt gedraaid, kan de parameter voor de Reader Mode worden gepubliceerd. Voor de initiele vulling van de datawarehouse tabel kan dan incidenteel de waarde “Normal” worden meegegeven, maar in de maandelijkse automatische run zal de waarde “Update” ingevuld worden. Dan worden alleen records aangeboden die gewijzigd zijn sinds de – in FME geregistreerde – datum. Vanzelfsprekend zal de workspace aangepast moeten worden, zodat de updates ook daadwerkelijk in de correcte modus worden geschreven in de uiteindelijke writer.
Ingebouwde functies
FME is een intuïtieve en krachtige tool. Initiële vulling en bijhouding van datawarehouse tabellen is, zeker wanneer die tabellen ook een geo-component bevatten, typisch een taak voor FME. Vaak worden in FME echter complexe systemen gebouwd, waarbij delen van de gebouwde functionaliteit deel uitmaken van ingebouwde functies in FME. Dat die, zoals in dit geval, minder direct voor de hand liggen, maakt voor mij FME eigenlijk alleen maar leuker.